Centralized logging and tracing for your microservices
No additional client libraries needed in your service code
MENU


API proxy for logging and controlling traffic between microservices
No additional client libraries needed in your service code
Define both global traffic rules and custom rules for individual services
 orders-shipping custom configuration_2.png)

No changes required in how your services are currently deployed
Apex is an API proxy for microservices. It provides one place to log and control service-to-service traffic.
Apex is designed for small teams that have just begun migrating from a monolith to a microservices architecture. While microservices bring many benefits such as faster deployment cycles, they also bring a host of new challenges by relying on the network for service-to-service communication. As network communication is unreliable and has latency, faults become more likely to occur, leading teams to have to spend more time diagnosing network-related faults, and writing pre-emptive fault-handling logic within each service. [1]
Some current solutions exist to help teams perform these tasks faster. Client libraries can be imported into each service’s code to automate networking concerns, an API gateway can be inserted in front of all services to handle incoming traffic, and for large systems, a service mesh is often deployed to abstract away networking concerns from services altogether. These are all valid solutions with their own set of trade-offs.
For a small team running their first few microservices, however, none of the existing solutions provide the right set of trade-offs: optimized for service-to-service traffic, and ease of deployment and operation, over high availability and scalability. These are the trade-offs that underpinned Apex’s design.
With Apex, a user can view the logs for all service-to-service traffic by querying just one table, while grouping all requests and responses that belong to the same workflow. They can also define and update traffic rules such as the number of times to retry a request in one configuration store.
To understand how Apex makes it easier to work with microservices, it is important to first understand what microservices are. This, in turn, requires understanding that the microservices architecture is a choice, the other choice being, of course, a monolith.
In a monolithic architecture, there is typically just one application server (the ‘monolith’) that holds all the business logic. In some cases, this application server alone is already sufficient to serve an application to a user (e.g. a website with just static HTML). More likely though, the application will also generate some user data that must be persisted, and so the monolithic application server will also transfer data to and from a database server.
 Monolith.png)
Consider the above example of a monolithic system that serves an e-commerce store to users. The business logic in the app server can be organized into classes or modules, or more generally, ‘subsystems’, that encapsulate related functionality e.g. manipulating customer data, checking and updating inventory, creating shipments. These subsystems can each expose an interface of methods, or more generally ‘behaviors’, that can be invoked by each other to facilitate communication between them.
As method or function calls take place within the same running process in memory, they are reliable and very fast, with latency often measured in microseconds [2].
 In-process method calls.png)
Another possible monolithic architecture is to further decouple the data store for each
subsystem, by separating it into multiple database servers. For example, the
customers subsystem and the orders
subsystem can be connected to separate database servers, if that is deemed to be e.g. more
flexible or scalable for a particular need.
 Monolith with multiple databases.png)
A simple analogy for a monolithic application is a small business run by just one owner. The owner has to do everything - sales and marketing, procurement, operations, finance, IT. There may be one central log book that keeps track of all business data, or the owner could use several ‘persistent data stores’ in parallel e.g. CRM system for sales data, accounting software for financial data, ERP system for inventory data, pen and paper for tax filings.
The microservices architecture differs from the monolith in two major ways. First, subsystems are decoupled even further. Each subsystem is deployed independently to its own app server as a standalone ‘application’, or ‘service’, and the current best practice is for every service to have its own database [3].
 Microservices with multiple databases.png)
Secondly, subsystems now communicate over the network via HTTP requests, rather than
through in-process method invocations. So for example, if our orders service
needs to create a new shipment, it might do this by sending a POST request to
the /shipments endpoint of the shipping
service, and attaching any other relevant information in the request body.
 Microservices communicating over the network.png)
Going with the same analogy of a small business, the microservices architecture is comparable to a small team of several members (or ‘services’) who each specialize in one function. For example, these could include a salesperson, a marketer, an operations manager, accountant/bookkeeper and an IT manager. Now, function-to-function communication no longer happens in the owner’s head (or ‘in-process’); instead, different team members must communicate with each other in person, on the phone or by email (or ‘over the network’) to get things done.
As we shall see, the use of the network for communication between subsystems is the key enabler for many of the benefits of the microservices architecture, but also the main culprit behind many of its drawbacks.
A first benefit of microservices is a wider choice of technologies for service developers. [4] The network boundaries between services free them from having to use the same technology stack. As long as each service maintains a stable network interface, or API, for other services talking to it, it is free to choose the language or framework that is most optimal for implementing its business logic.
 Microservices with different stacks.png)
Arguably the most defining benefit, though, is the option to deploy subsystems independently of each other. [5] With subsystems now deployed to independent services that each have a smaller scope, redeploying any one subsystem incurs less overhead and so it becomes practical to redeploy each service more frequently. This enables teams to ship new features faster and reap the corresponding business benefits sooner.
More concretely, in our e-commerce example app, as soon as a feature in the
orders service is ready, orders can be redeployed. As long as
orders’s API remains the same before and after the deployment, other services
need not even know that a redeployment took place. On the other hand, if
notifications’s logic rarely changes, then that service can simply continue
to operate untouched.
 Redeploying one microservice.png)
Independent redeployment also enables independent scaling. [6]
If our orders service is the first to reach its capacity, then we can simply
upgrade orders to a more powerful server or deploy more replicas of
orders, without having to also replicate every other service. Yet again, as
long as the replicated orders service retains the same API before and after
scaling, the other services can continue to operate in the same way as though nothing
happened. The result is fewer large-scale system-wide redeployments and higher utilisation
of provisioned resources, leading to savings in engineering time and costs.
 Scaling microservices.png)
We have now seen how the network boundaries between microservices result in several major benefits over the monolithic architecture. The network, however, comes with baggage, and relying heavily on it to communicate between subsystems introduces an entire new dimension of challenges.
Recall that in a monolith, subsystems are simply classes or modules that communicate through method invocations within the same process in memory. In contrast, in a microservices architecture, equivalent calls are now sent between services using HTTP requests and responses over the network.
 In-process method calls vs network hops.png)
As any sufficiently heavy user of the internet will have experienced, the network is unreliable and has latency. That is, networks can disconnect for any number of reasons, and network traffic can sometimes take a long time to reach its destination. Even though in production, services are likely deployed to state-of-the-art data centers run by large cloud providers, network faults still can and do occur.
 Network faults.png)
Such faults introduce a whole new class of problems for developers - not only do they have to ensure their service code is bug-free, now they also have to diagnose unexpected network faults, and add logic to service code that preempts network faults by providing compensating behaviors (e.g. displaying a ‘network down’ page to users, or retrying the same request a few seconds later).
Diagnosing a network fault can be especially cumbersome when a single workflow passes
through multiple services. Consider a user placing an order on our e-commerce example app,
and suppose the orders service needs to first update inventory in
inventory, then create a shipment in shipping. This one workflow
involves 3 services with at least 3 network hops between them. If the order placement
eventually fails, what caused that to happen?
 Network fault in multi-service workflow.png)
To find out, a developer would have to trace the user’s initial POST request
through the entire system. Since each service generates its own logs, the developer would
have to first access orders’s logs, track down the request that failed,
follow the request to the next service (in our case, the inventory service),
access inventory’s logs, and so on, until they pinpoint the exact request
that failed. This can be a laborious and slow process.
Other times, a network fault may be totally random, and a request should simply be retried again. But how long should the requesting service wait before retrying again? How many times should it retry before giving up? If too soon or too many, then all the retries could overwhelm the responding service. Such logic must be defined thoughtfully.
 Retry logic.png)
The next question becomes: where should all this logic be defined? For some teams, the
first answer to this question is in HTTP client libraries that are imported into each
service’s code. [7] So if the orders service is
written in Ruby, then it would require a gem that provides a configurable
client for making HTTP requests to other services. Another service written in Node might
import a similar package into its code.
Often, these libraries can also handle logging, as well as other networking and infrastructure concerns, such as caching, rate-limiting, authentication etc.
Teams with more resources may go further, by having each service’s owner write a client library for every other service that calls it. This is already common practice when working with popular external APIs; for example, Stripe provides dozens of official and third-party libraries in different languages that abstract away the logic for calling its APIs. [8] Similarly, in a large team, each service’s owner may be tasked with writing a new client library for every requesting service that uses a different language.
 New client library for every language.png)
Needless to say, this solution becomes less and less manageable as the number of services grows. Every time a new service is built in a new language, every other service owner must write a new client library in that language. More critically, updating fault-handling logic now incurs a great deal of repetitive work. Suppose the CTO wishes to update the global defaults for the retry logic; developers would now have to update the code in multiple client libraries in every service, then carefully coordinate each service’s redeployment. The greater the number of services, the slower this process becomes. [9]
 Microservices with client libraries.png)
With microservices becoming increasingly popular, a number of solutions have emerged to help teams overcome these challenges. Here we explain how two of these solutions - the API gateway and the service mesh - compare with each other.
Both of these solutions in fact share the same building block - a proxy server.
 Proxy server as building block.png)
A proxy is simply a server that sits on the path of network traffic between two communicating machines, and intercepts all their requests and responses. These machines could represent a client sending a request to another server, or for our purposes, two internal services communicating within the same architecture.
 Proxy server.png)
In the above diagram, orders does not send an HTTP request directly to
shipping; instead, it addresses its request to a host belonging to
proxy (i.e. proxy.com). In order for proxy to know
that orders actually wants to send its request to shipping,
orders must specify shipping’s host (i.e.
shipping.com) in another part of the request e.g. in the
Host header value.
When proxy receives a response back from shipping, it simply
forwards the same response back to orders.
At its core, an API gateway is simply a proxy server (more precisely, a ‘reverse proxy’ [10]). When used with microservices, one of its primary functions is to provide a stable API to clients and route client requests to the appropriate service. [11]
 API gateway.png)
It is certainly possible to deploy microservices without an API gateway. In such an architecture, whenever the client sends a request, it must already know which service to send the request to, and also the host and port of that service. This tightly couples the client with internal services, such that any newly added services, or updates to existing service APIs, must be deployed at the same time as updates in the client code. Such an architecture can be difficult to manage, as clients cannot always be relied upon to update immediately (e.g. mobile apps cannot be easily forced to update); even if they can, doing so would still incur additional engineering that could be avoided.
 Microservices without API gateway.png)
With an API gateway, developers are largely free to update internal services while still providing a stable API to clients.
 API gateway's stable API.png)
In addition to routing requests, the API gateway also provides one place to handle many concerns that are shared between services, such as authentication, caching, rate-limiting, load-balancing and monitoring.
 API gateway's features.png)
In a way, an API gateway can be thought of as a receptionist at a large company. Any visitor does not necessarily have to know which employees are present in advance, or how different teams work together to complete specific tasks. Instead, they simply speak with the receptionist, who then decides, based on the visitor’s identity and stated purpose, which company employee to notify, and/or what access to grant to the visitor.
Let us revisit the challenges that were described back in Section 3: 1) diagnosing faults in workflows that span multiple microservices, and 2) managing fault-handling logic that is similar across services.
If the API gateway already provides one place to manage networking concerns, perhaps it is already a sufficient solution to these challenges? For example, instead of deploying it as a ‘front proxy’ that sits in front of all services, we could deploy it in a different pattern than it was intended for - as a proxy that sits between services internally. Would this not already provide the one place to log all service-to-service requests and responses, and define fault-handling logic like retries?
 Deploying API gateway internally.png)
In theory, this is certainly possible, but in practice, existing API gateway solutions are not ideal options for this.
Optimized to handle [client-server] traffic at the edge of the data center, the API gateway ... is inefficient for the large volume of [service-to-service] traffic in distributed microservices environments: it has a large footprint (to maximize the solution’s appeal to customers with a wide range of use cases), can’t be containerized, and the constant communication with the database and a configuration server adds latency.
- NGINX, maker of the popular open-source NGINX load balancer and web server [12]
In short, although the API gateway looks close to the solution we need, existing solutions on the market come built-in with many extra features that are designed for client-server traffic, making them a poor fit for managing service-to-service traffic.
 API gateway's extra features for client-server traffic.png)
That is not to say a solution like an API gateway is completely out of the question. As we shall see in Section 5, the API gateway pattern was a major source of inspiration for Apex’s solution.
The service mesh is another existing solution to the challenges with microservices that were outlined in Section 3. As mentioned previously, it also builds upon the proxy server.
The service mesh is a highly complex solution, and we once again approach it through the analogy of a company. Consider a large team of people (analogous to services) who all communicate directly with each other.
 Everybody talks to everybody.png)
As the team size grows, team members will likely find themselves spending more and more time handling these scenarios:
Managing these communication-related issues would take away time and focus from each team member’s core responsibilities.
In this example, adding a service mesh is analogous to giving every team member a personal assistant (PA), who intercepts all incoming and outgoing messages and handles all the above tasks. This team structure would free team members from having to handle communication-related tasks, and allow them to focus more on their core responsibilities.
 Team members with their own PA.png)
In an actual service mesh, the PA would instead be a proxy server, known as a ‘sidecar proxy’. Each service is deployed alongside its own sidecar proxy, which intercepts all requests and responses to and from its parent service, and handles all the networking and infrastructure concerns we listed above, such as retry logic, rate-limiting etc. As a result, each service’s code can focus on its main business logic, while outsourcing networking and infrastructure concerns to the service’s sidecar proxy. [13]
 Services and sidecar proxies.png)
In addition to the sidecar proxies, the service mesh has one other important component - a central configuration server.
Back in our hypothetical company, a configuration server is akin to a centralized folder containing data on team members and company policies e.g. who is on leave, who is working reduced hours, which secure channels to use, who has access to what information. Each personal assistant (PA) would have their own copy of this information to help them handle communication quickly, but whenever anything is updated in the centralized folder e.g. by the COO or HR Director, the changes are immediately sent to each PA, so that PAs always have the most up-to-date information in their own copies.
 Centralized folder with company policies and team info.png)
In the same way, the configuration server in a service mesh provides one place to update network traffic rules, such as logic for retries, caching, encryption, rate-limiting, routing. The configuration server is the source of truth for this information, but each sidecar proxy also has a cached copy of the information. Whenever the configuration server gets updated, it propagates the changes to each sidecar proxy, which then applies the changes to its own cached copy. [14]
 Services and configuration server.png)
Again, let us revisit the challenges that were described back in Section 3: 1) diagnosing faults in workflows that span multiple microservices, and 2) managing fault-handling logic that is similar across services.
The service mesh provides a robust solution to these challenges. The configuration server provides one place to define and update fault-handling logic; each sidecar proxy can be responsible for generating logs and sending them to one place to be stored, and also for executing fault-handling logic. Moreover, without any single point of failure or one single bottleneck, the architecture is resilient and highly scalable. [15]
 Service mesh as solution to microservices challenges.png)
However, as with so many tools, rich functionality begets complexity. Implementing a full service mesh more than doubles the number of components in the architecture that must now be deployed and operated. In addition, both the sidecar proxy and its parent service are usually containerized to run alongside each other in the same virtual server. [16] If any existing service is currently deployed without a container, then developers must now containerize it and redeploy it. More domain expertise must be acquired, and significant engineering effort expended.
As we have seen, solutions certainly exist to handle the challenges we described with microservices. Each existing solution embodies a different set of trade-offs.
 API gateway and service mesh trade-offs.png)
For some teams, neither an API gateway nor a service mesh provide the right set of trade-offs. Consider a small team that are just beginning to migrate their monolith to include a few microservices. For ease of deployment, most of the services have been deployed to Heroku, or another platform as a service (PaaS) solution.
It is likely that this team will have already experienced the challenges we mentioned back in Section 3: 1) diagnosing faults in workflows that span multiple microservices, and 2) managing fault-handling logic that is similar across services.
For this team, a solution with the following trade-offs are needed:
 Apex trade-offs.png)
These are precisely the trade-offs we chose when building Apex.
Apex’s architecture includes 5 components:
 Apex architecture.png)
Apex’s core component, the apex-proxy server sits on the path of network
traffic between every pair of communicating microservices, such as that between
orders and shipping above. In the case of systems with more than
two services, the following diagram shows how Apex would be deployed.
 Mediating all service-to-service traffic.png)
Recall that an API gateway is just a proxy server that handles all client-server traffic coming into a system, and routes client requests to the correct service. In a similar way, Apex can be thought of as a stripped-down, internally deployed API gateway, which routes not traffic between clients and servers, but traffic between services.
Zooming further into apex-proxy, there are several middleware layers that
each provide additional functionality beyond simple proxying, such as authentication,
routing, retries and logging.
 Apex architecture with middleware.png)
Since apex-proxy intercepts all network traffic between microservices, it is
able to aggregate logs for every request and response, and send them to
apex-logs-db to be persisted and queried in one place.
 apex-logs-db.png)
Additionally, apex-proxy provides the ability to trace requests and responses
that belong to the same request-response cycle. Any request that comes into
apex-proxy is given an extra correlation-id HTTP header value
(f84nw2 in the example diagram below), if it doesn’t have one already, before
being logged. This same correlation-id value is then also included as the
request is forwarded to the responding service. When a response comes back from the
responding service, Apex adds this same correlation-id value to the response,
before forwarding this updated response back to the requesting service. As a result, all
requests and responses belonging to the same request-response cycle have the same
correlation-id value when they are logged, making it easy to query them
together.
 Adding correlation_id header.png)
This same feature also makes it possible to connect requests and responses belonging to
workflows that span multiple services. As long as each service adds some logic to
propagate any correlation-id header value that already exists in incoming
requests, then all requests and responses belonging to the same workflow will have the
same correlation-id value in apex-logs-db.
 Tracing multi-service workflow.png)
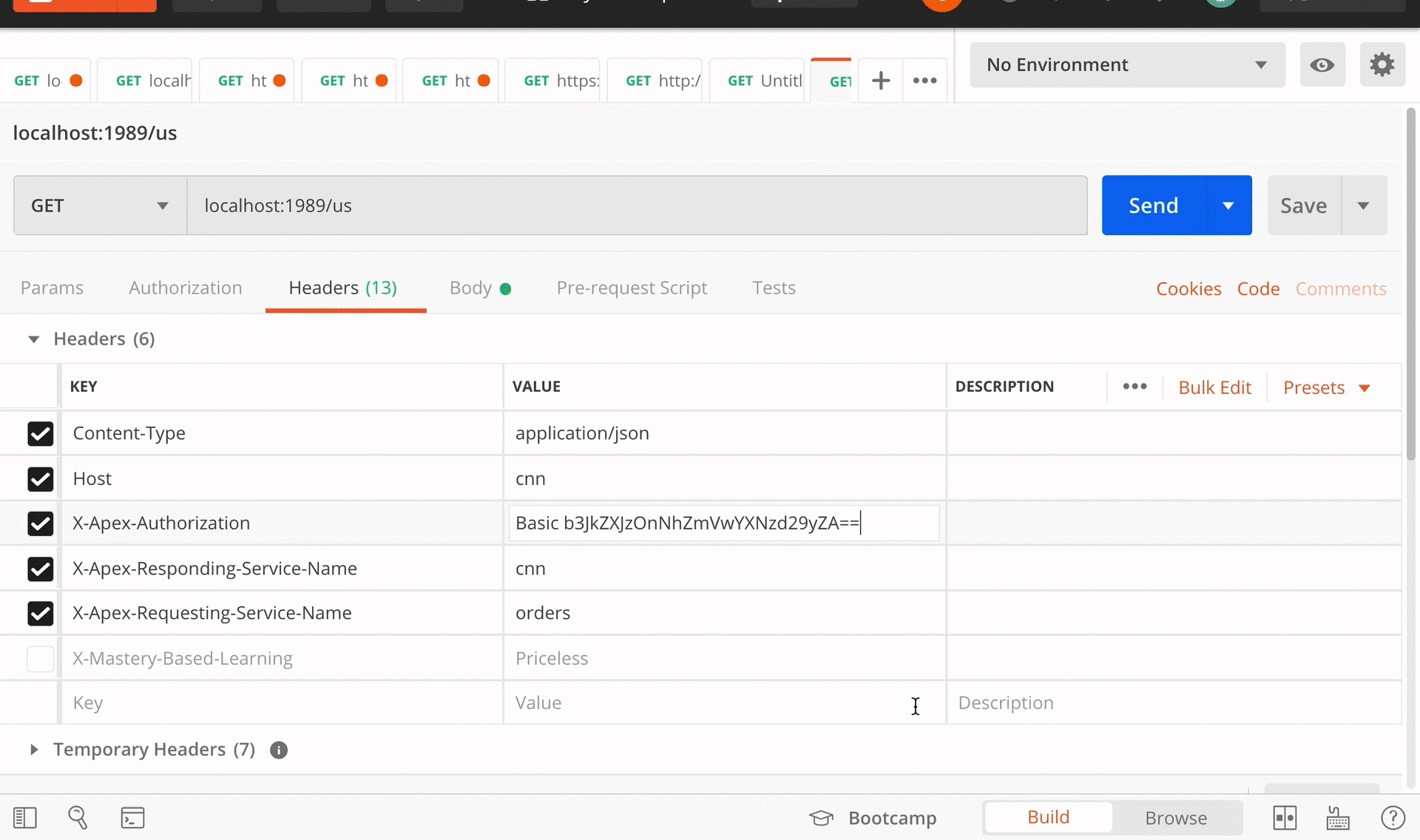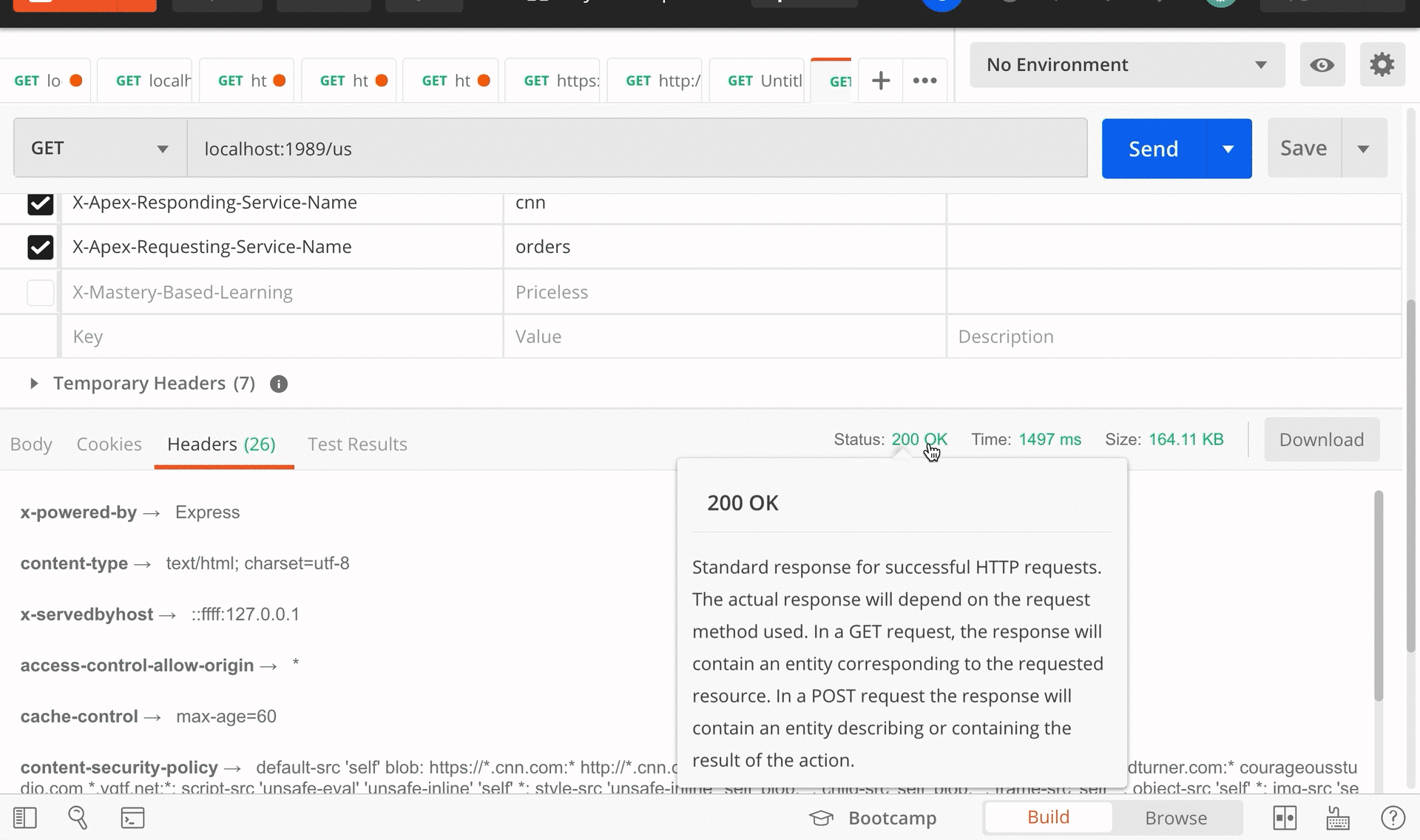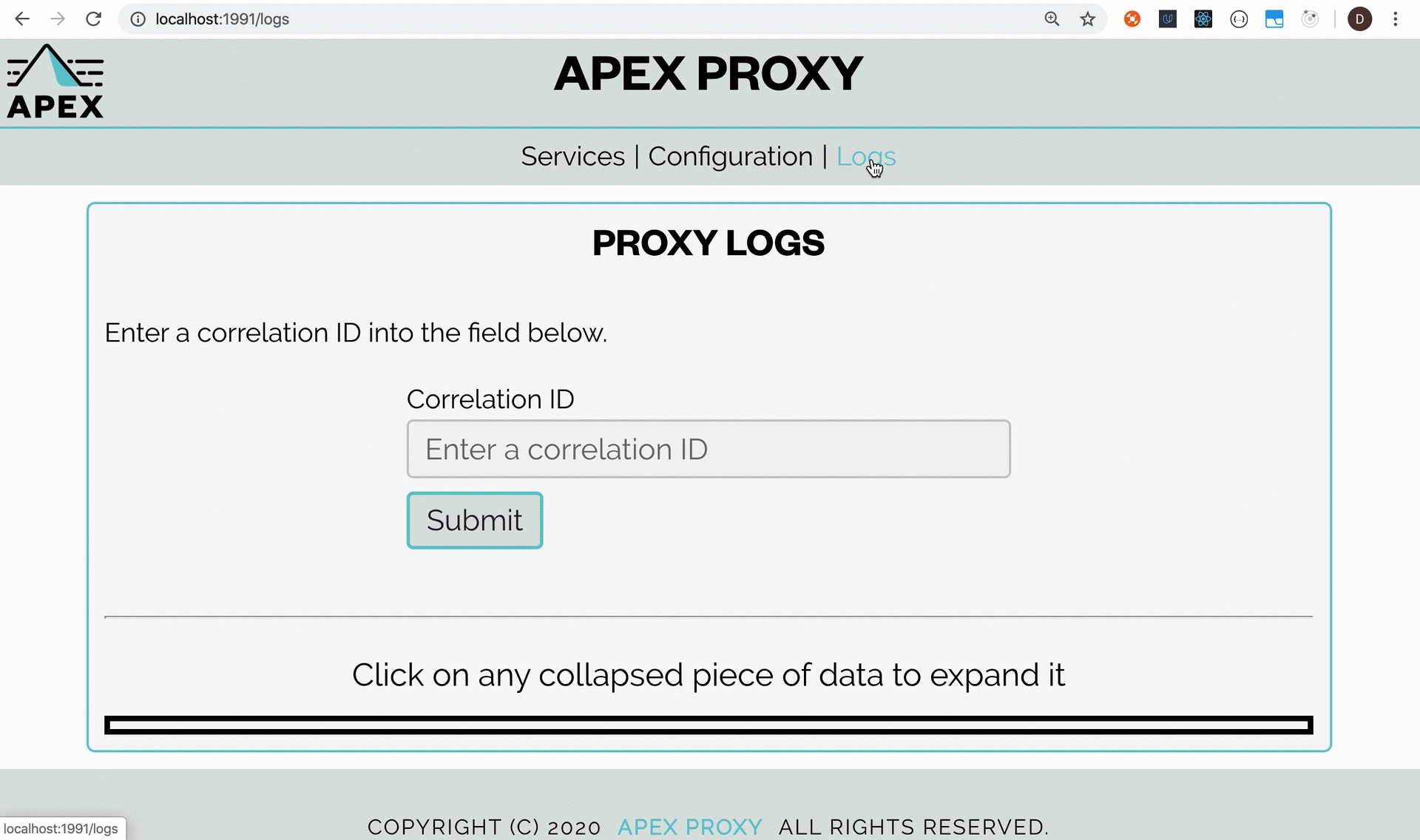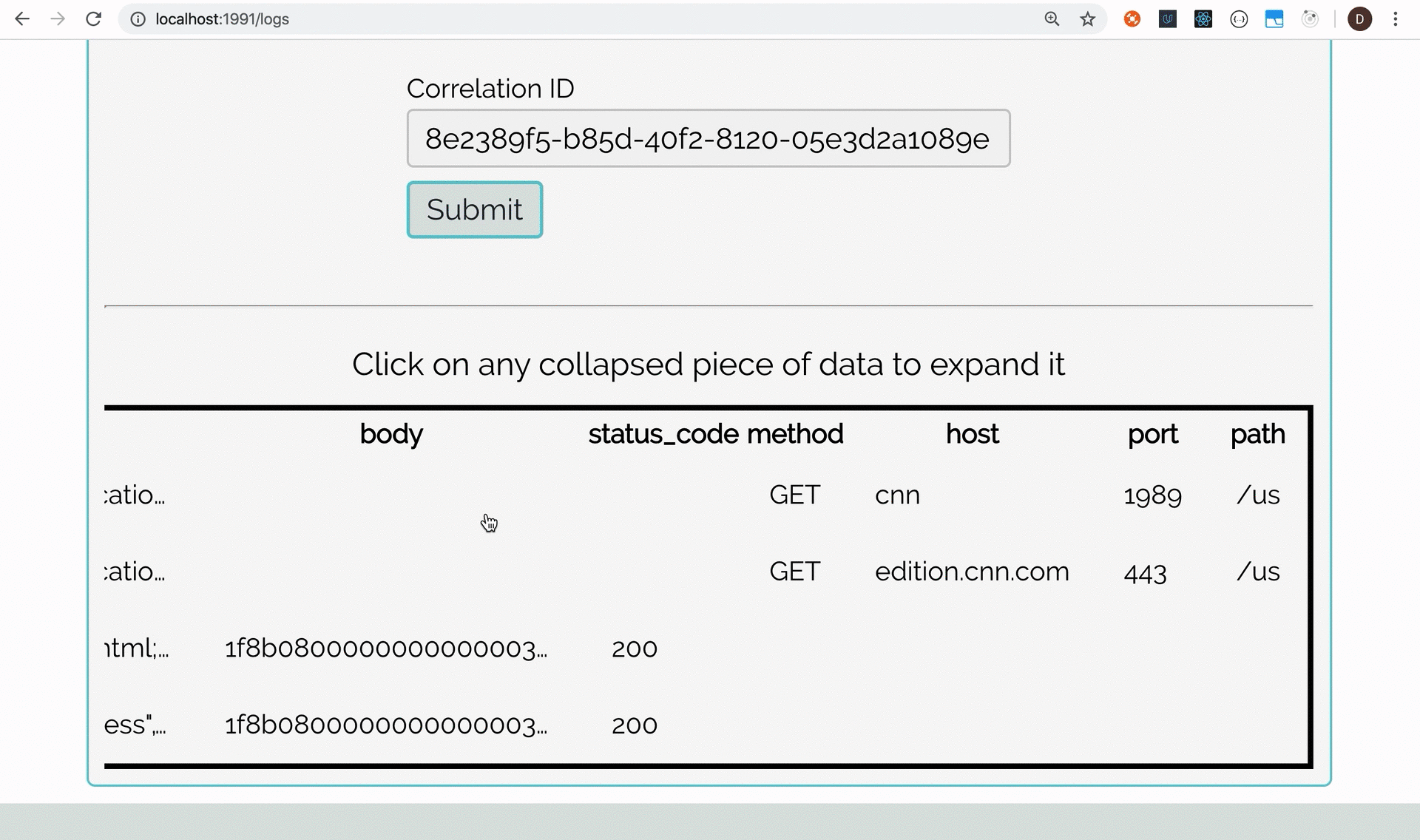
Now, figuring out where a request failed within a workflow is just a matter of querying
apex-logs-db for that one correlation-id value. This solves our
first problem of diagnosing faults in workflows that span multiple microservices.
 Querying logs by correlation_id.png)
Below, we demonstrate this feature on an actual deployed instance of Apex.

Similar to the service mesh, Apex also has a single configuration server, the
apex-config-store, where developers can define logic for retries, routing
etc. In this way, Apex can be thought of as a stripped-down service mesh.
 apex-config-store.png)
apex-config-store contains the following configuration data:
service-credentials is used for authentication. It stores the list of
service names along with their passwords. Every service that sends a request to Apex
must authenticate itself with a token generated using its name and password.
service-hosts is used for routing. It lists the IP address or domain name
where each service can be found.
default-default is used for defining global defaults for service-to-service
traffic. In the above diagram, currently by default a request times out if a response is
not received within 3,500 ms, and can be retried a maximum of 4 times. Each new retry
attempt must wait, or ‘back off’, for 5,000 ms after the last failed request.
orders-shipping and shipping-inventory are examples of
service-specific rules that override the global defaults:
orders sends a request to shipping, requests time
out after 5,000 ms, and can only be retried no more than 2 times, with a backoff of
2500 ms.
shipping sends a request to inventory, however,
requests time out after 2,000 ms, and there shall be no retries at all.
For every request sent to Apex, apex-config-store is queried for
authentication, routing and retry logic - in that order. Only after all three are complete
do requests get forwarded onto the responding service.
 apex-proxy + apex-config-store.png)
With this one place to define and update configuration data, Apex’s architecture provides a solution to our second problem of managing fault-handling logic (as well as other network concerns) that is often similar across services.
Below is the actual Apex UI for defining retry logic for when the
orders service calls the shipping service.
Applying the same company analogy that we used for the service mesh, Apex is comparable to
having just one team assistant (apex-proxy) for the whole team, rather than
one personal assistant per team member, mediate all communication between team members.
Every time any team member needs to communicate with another team member, they send their
messages through the team assistant. On every incoming message, the team assistant checks
a centralized folder (apex-config-store) containing all the relevant
information on team members and company policies, to verify the identity of the sender,
determine who should receive the message, as well as how many times to retry should the
first attempt fail.
Though Apex provides a solution to the two microservices challenges that were described back in Section 3, it comes with trade-offs, namely lower availability, and lower scalability.
One of the strengths of the full service mesh is that there is no one component that sits
on the path of all service-to-service traffic. If a sidecar proxy crashes or gets
overloaded, only its parent service becomes unavailable, while the remaining services can
continue to operate normally. With Apex, however, the apex-proxy becomes a
single point of failure and traffic bottleneck. Any outage in apex-proxy will
halt all service-to-service traffic and render the entire system unavailable.
Ultimately, there is an inherent trade-off between the number of proxies in the system (and hence availability and scalability), and how easy it is to deploy and operate the system. Apex and service meshes occupy opposite ends of this spectrum.
 Apex and service meshes on spectrum.png)
Despite the seemingly divergent set of trade-offs between Apex and the service mesh, Apex’s architecture is in fact acknowledged by several service mesh vendors as a possible transitional architecture on the journey toward a full service mesh. NGINX calls this architecture a ‘Router Mesh’ [17]; Citrix calls it a ‘Service Mesh Lite’ [18], and Kong calls it an ‘Internal API gateway’ [19].
Therefore, any team that adopts Apex’s architecture can rest assured that they are not taking a path that is mutually exclusive to eventually adopting a full service mesh. The truth is quite the opposite - this architecture is “relatively easy to implement, powerful, efficient, and fast”, and forms part of a “progression” toward a service mesh [20].
When implementing Apex, we made technology choices based on the trade-offs we described in Section 5.1. In particular, we prioritized ease of deployment and operation over feature-richness, high availability and high scalability. The technologies we ended up choosing include Node.js and Express.js, TimescaleDB, Redis, React and Docker.
 Apex architecture with technologies.png)
Below, we briefly elaborate upon each of these choices.
apex-proxy - Node.js and Express.js apex-proxy in Node and Express.png)
For the main proxy server, we had the choice between using any popular web development framework (e.g. Rails), and building atop an existing proxy (e.g. Envoy, NGINX). Since one of our design goals was to be ‘simply to deploy and operate’, we preferred a solution that did not come built-in with any extra features that are irrelevant to our target user. With this in mind, we decided on the “fast, unopinionated, minimalist” Express.js framework [21] built in Node.js, a language known for its ability to “handle a huge number of simultaneous connections with high throughput” [22] and widespread usage among developers.
apex-logs-db - TimescaleDB apex-logs-db in TimescaleDB.png)
The request and response logs generated by apex-proxy are a type of
time-series data. [23] To store them in one place, we chose
TimescaleDB, a time-series database that can ingest data at a rate of more than 100,000
rows per second, even as a database reaches billions of rows [24]. This high ingestion rate mitigates the risk that writing logs to storage will become a
bottleneck in the system.
apex-config-store - Redis apex-config-store in Redis.png)
One of Apex’s core features is providing service owners with one place to modify service
information (e.g. register their service, generate new credentials for authentication),
and update fault-handling logic (e.g. retry logic) for their own service. To enable this,
we had several options for where to store the configuration data: 1) in an environment
file that is loaded into memory when apex-proxy spins up, 2) in a file that
is read by apex-proxy for every request, or 3) in an external configuration
data store.
Option 1 of using an environment file was immediately ruled out, as it requires that the
apex-proxy process be restarted every time the file is updated. Between the
two remaining options, storing configuration in a file on disk leads to faster reads,
since in general disk IO is faster than fetching data over the network. However, files can
be easily corrupted, if say multiple processes write to the same file at the same time.
In the end, we decided on Option 3, and implemented a Redis key-value store that gets queried for configuration data on every request. Redis stores all its data in memory, and so enables reads at over 72,000 requests per second [25]. This somewhat makes up for Option 3’s slower read speed compared to Option 2. In addition, Redis persists data to disk once every second, ensuring that configuration data will remain intact even if the Redis instance crashes and must restart.
apex-admin-api - Node.js and Express.js apex-admin-api in Node and Express.png)
For convenience, we built a REST API that enables users to programmatically query their logs in TimescaleDB and update config data in Redis (as opposed to having to SSH into those instances and issue commands in the terminal). This API also provides the option for admins to build additional UIs for different access roles e.g. a logs-only UI for users who are not authorized to update configuration data.
apex-admin-ui - React apex-admin-ui in React.png)
Finally, apex-admin-ui communicates with the
apex-admin-api backend and provides service owners with a convenient way to
register new services, edit existing service information, add and edit custom
configuration, and query logs by correlation_id.
 Deploying in Docker containers.png)
Installing and running five interconnected components will likely be a time-consuming process fraught with unpredictable environment-specific errors. Standing by our design goal of being ‘simple to deploy and operate’, Apex’s components are all containerized using Docker, and deployed in a coordinated fashion with Docker Compose. This ensures Apex’s components are all deployed in the same (containerized) environment for every user.
As shown below, deploying Apex with Docker Compose locally requires just one
docker-compose up command.
Apex’s documentation also provides step-by-step instructions for deploying Apex to AWS’s Elastic Container Service (ECS).
Sending large request and response bodies from apex-proxy to
apex-logs-db can add significant latency to request-response cycles, spin up
long-running processes in apex-proxy that decrease its throughput, and fill
up apex-logs-db far faster than necessary.
To solve these problems, we ultimately chose to avoid decompressing any log bodies that arrive in a compressed format, and send logs asynchronously from an in-memory queue.
Quite simply, sending compressed bodies means fewer bytes transmitted and stored. For a
typical web page that arrives at apex-proxy in a compressed format (e.g.
CNN’s homepage), we found that sending the compressed body to
apex-logs-db typically took less than 1 second, compared with 5-10 seconds
for the decompressed version.
While keeping bodies compressed was a sensible choice, it came with the trade-off of
inconvenience for users of apex-logs-db, who must now take the extra step to
decompress bodies to make them human-readable again.
Queuing logs to be sent asynchronously has the effect of decoupling writes to
apex-logs-db from request-response cycles through apex-proxy. If
apex-proxy happens to receive a particularly large response body that must be
logged, it can simply enqueue this log, and move on to forwarding the response back to the
requesting service and then on to processing the next request. The request-response cycle
can complete regardless of when, or whether, the log eventually gets sent to
apex-logs-db.
Adding a queue in this way also lays the foundation for a further optimization - sending logs to TimescaleDB in batches. TimescaleDB’s own docs explain that this could further increase its data ingestion rate. [26]
However, this solution comes with two trade-offs. The first is that several large log queues within concurrent processes could consume a lot of memory, straining the host server. Given TimescaleDB’s high ingestion rate, we made the decision to accept this trade-off, in the belief that the logs will dequeue fast enough to avoid hitting such a limit.
The second trade-off is that should apex-proxy crash, any logs that have not
yet been dequeued would now be lost from memory. Since each individual log is relatively
unimportant data, we also deemed this an acceptable trade-off.
While containerizing TimescaleDB and Redis made deployment simpler for users, it also increased the risk of losing logs and configuration data. This is due to the ephemeral nature of Docker containers. [27]
Fortunately, Docker containers support ‘volumes’, a mechanism to persist data to a
container’s host filesystem, and beyond the container’s lifespan. [28] When deploying containers locally with Docker Compose, enabling this feature requires
just an extra line of code in the docker-compose.yml configuration file.
Deploying Docker containers to AWS’s Elastic Container Service (ECS), though, requires more care. ECS offers two launch types [29]: the EC2 launch type provides more control, by allowing developers to choose the type and quantity of EC2 instances to provision for their containers. Its downside is that it requires more steps to deploy. The Fargate launch type, in contrast, abstracts away the entire resource-provisioning process, reducing the deployment process to running just 6 or so commands. Crucially, only the EC2 launch type supports Docker volumes. [30]
We had initially wanted to support the Fargate launch type, in alignment with our design goal of being ‘simple to deploy’. However, it was clear to us that the ability to persist logs and configuration data beyond the lifecycle of individual containers will be important for any Apex user, and in the end we spent a significant amount of extra time configuring Apex to support the EC2 launch type.
Apex, as is, represents a single point of failure for a system. To protect it from being
overwhelmed by bursty traffic, a best practice is to deploy a FIFO (‘first in, first out’)
queue in front of apex-proxy. Another option we are considering is to deploy
a standard queue without FIFO guarantees, which offers higher throughput rates, but
requires additional middleware in apex-proxy to ensure messages are consumed
in the right order.
While Docker volumes offer strong persistence guarantees for Apex’s logs and configuration
data, the compute instances (e.g. AWS EC2) hosting the containers are ephemeral and not
suitable for long-term storage. For users who need even stronger persistence guarantees,
apex-logs-db and apex-config-store can be configured to
periodically back up data to a cloud storage service (e.g. AWS S3 and S3 Glacier).
apex-proxy
Currently, every incoming request to Apex triggers multiple reads from the Redis
apex-config-store. As Apex is designed for small teams with a finite and
small number of services, most of these reads from Redis will be for the same
configuration data. Therefore, we can significantly reduce the read rate by caching a copy
of all configuration data in memory within apex-proxy, and updating the cache
whenever any user makes a change on Redis.
We are looking for opportunities. If you liked what you saw and want to talk more, please reach out!

New York, NY

London, UK